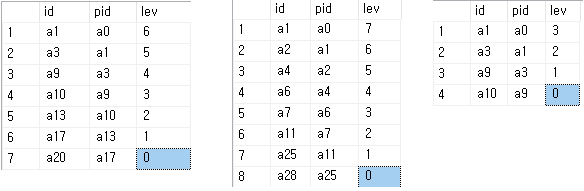
USE [TEST_DB]
GO
CREATE TABLE [dbo].[t_test](
[id] [varchar](45) NOT NULL,
[pid] [varchar](45) NOT NULL,
[data] [varchar](100) NOT NULL,
CONSTRAINT [PK_t_test] PRIMARY KEY CLUSTERED
(
[id] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a1', N'a0', N'그림1')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a10', N'a9', N'그림10')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a11', N'a7', N'그림11')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a12', N'a8', N'그림12')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a13', N'a10', N'그림13')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a14', N'a10', N'그림14')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a15', N'a10', N'그림15')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a16', N'a13', N'그림16')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a17', N'a13', N'그림17')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a18', N'a14', N'그림18')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a19', N'a15', N'그림19')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a2', N'a1', N'그림2')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a20', N'a17', N'그림20')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a21', N'a4', N'그림21')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a22', N'a21', N'그림22')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a23', N'a5', N'그림23')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a24', N'a11', N'그림24')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a25', N'a11', N'그림25')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a26', N'a12', N'그림26')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a27', N'a9', N'그림27')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a28', N'a25', N'그림28')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a29', N'a22', N'그림29')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a3', N'a1', N'그림3')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a30', N'a2', N'그림30')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a4', N'a2', N'그림4')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a5', N'a4', N'그림5')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a6', N'a4', N'그림6')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a7', N'a6', N'그림7')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a8', N'a3', N'그림8')
INSERT [dbo].[t_test] ([id], [pid], [data]) VALUES (N'a9', N'a3', N'그림9')
GO
















































 코스닥_보유현황.7z.001
코스닥_보유현황.7z.001



 WICS_code.xlsx
WICS_code.xlsx





