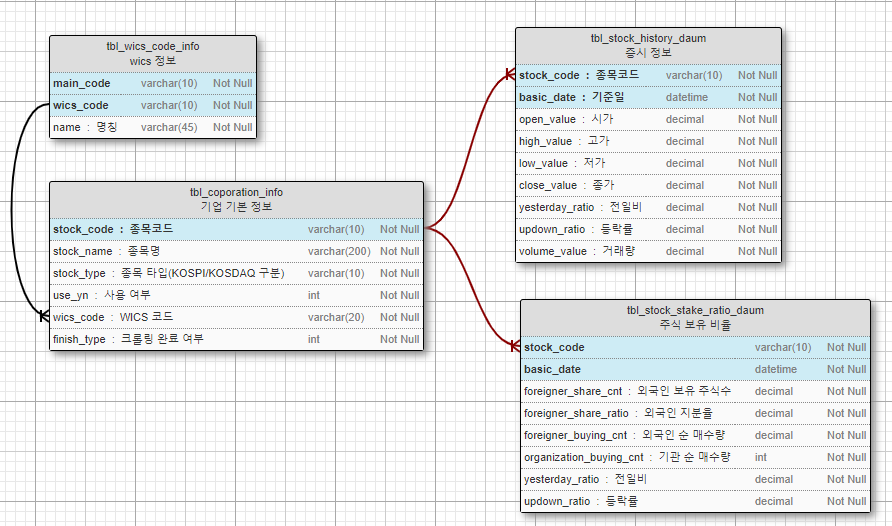
다음에서 크롤링한 20년치 증시 데이터 입니다.
MYSQL 백업파일이며, ERD 첨부 합니다.
일자별 가격, 외국인 보유 비율 등 입니다.
DB 백업파일 다운로드 주소 : http://bitly.kr/R65ncg << 2020-07-29 다운로드 가능합니다.
첨부된 백업파일의 복원은 아래 게시물을 참고해 주시길 바랍니다.
'Database & Data > Data' 카테고리의 다른 글
| 대한민국 환율 데이터 (2006-01-02 ~ 2021-06-18) (0) | 2021.06.19 |
|---|---|
| 다음-코스닥 보유 현황 약10년치 (2007-02-23 ~ 2017-12-28) 데이터-CSV (0) | 2017.12.30 |
| 다음-코스닥 증시 약20년치 (1998-02-02 ~ 2017-12-28) 데이터-CSV (6) | 2017.12.29 |
| 다음-코스피 증시 약20년치 (1983-05-03 ~ 2017-11-07) 데이터-CSV추가 (7) | 2017.11.09 |
| 10년치 코스피 기업별 외국인/기관 보유 현황 (2007-02-23 ~ 2017-11-08) (4) | 2017.11.08 |












































 Stock_Crawling 2.7z
Stock_Crawling 2.7z





 WICS_code.xlsx
WICS_code.xlsx
 Excel_Insert.zip
Excel_Insert.zip




